

This post is co-written with Shamik Ray, Srivyshnav K S, Jagmohan Dhiman and Soumya Kundu from Twilio.
Today’s leading companies trust Twilio’s Customer Engagement Platform (CEP) to build direct, personalized relationships with their customers everywhere in the world. Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth and customer service, and many more engagement use cases in a flexible, programmatic way. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create magical experiences for their customers. Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. This post outlines the steps AWS and Twilio took to migrate Twilio’s existing machine learning operations (MLOps), the implementation of training models, and running batch inferences to Amazon SageMaker.
ML models don’t operate in isolation. They must integrate into existing production systems and infrastructure to deliver value. This necessitates considering the entire ML lifecycle during design and development. With the right processes and tools, MLOps enables organizations to reliably and efficiently adopt ML across their teams for their specific use cases. SageMaker includes a suite of features for MLOps that includes Amazon SageMaker Pipelines and Amazon SageMaker Model Registry. Pipelines allow for straightforward creation and management of ML workflows while also offering storage and reuse capabilities for workflow steps. The model registry simplifies model deployment by centralizing model tracking.
This post focuses on how to achieve flexibility in using your data source of choice and integrate it seamlessly with Amazon SageMaker Processing jobs. With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform.
Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources.
In this post, we show you a step-by-step implementation to achieve the following:
Use case overview
Twilio trained a binary classification ML model using scikit-learn’s RandomForestClassifier to integrate into their MLOps pipeline. This model is used as part of a batch process that runs periodically for their daily workloads, making training and inference workflows repeatable to accelerate model development. The training data used for this pipeline is made available through PrestoDB and read into Pandas through the PrestoDB Python client.
The end goal was to convert the existing steps into two pipelines: a training pipeline and a batch transform pipeline that connected the data queried from PrestoDB to a SageMaker Processing job, and finally deploy the trained model to a SageMaker endpoint for real-time inference.
In this post, we use an open source dataset available through the TPCH connector that is packaged with PrestoDB to illustrate the end-to-end workflow that Twilio used. Twilio was able to use this solution to migrate their existing MLOps pipeline to SageMaker. All the code for this solution is available in the GitHub repo.
Solution overview
This solution is divided into three main steps:
- Model training pipeline – In this step, we connect a SageMaker Processing job to fetch data from a PrestoDB instance, train and tune the ML model, evaluate it, and register it with the SageMaker model registry.
- Batch transform pipeline – In this step, we run a preprocessing data step that reads data from a PrestoDB instance and runs batch inference on the registered ML model (from the model registry) that we approve as a part of this pipeline. This model is approved either programmatically or manually through the model registry.
- Real-time inference – In this step, we deploy the latest approved model as a SageMaker endpoint for real-time inference.
All pipeline parameters used in this solution exist in a single config.yml file. This file includes the necessary AWS and PrestoDB credentials to connect to the PrestoDB instance, information on the training hyperparameters and SQL queries that are run at training, and inference steps to read data from PrestoDB. This solution is highly customizable for industry-specific use cases so that it can be used with minimal code changes through simple updates in the config file.
The following code shows an example of how a query is configured within the config.yml file. This query is used at the data processing step of the training pipeline to fetch data from the PrestoDB instance. Here, we predict whether an order is a high_value_order or a low_value_order based on the orderpriority as given from the TPC-H data. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. You can change the query for your use case within the config file and run the solution with no code changes.
The main steps of this solution are described in detail in the following sections.
Data preparation and training
The data preparation and training pipeline includes the following steps:
- The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time. The queries that are used to fetch data at training and batch inference steps are configured in the config file.
- We use the FrameworkProcessor with SageMaker Processing jobs to read data from PrestoDB using the Python PrestoDB client.
- For the training and tuning step, we use the SKLearn estimator from the SageMaker SDK and the
RandomForestClassifierfrom scikit-learn to train the ML model. The HyperparameterTuner class is used for running automatic model tuning, which finds the best version of the model by running many training jobs on the dataset using the algorithm and the ranges of hyperparameters. - The model evaluation step checks that the trained and tuned model has an accuracy level above a user-defined threshold and only then register that model within the model registry. If the model accuracy doesn’t meet the threshold, the pipeline fails and the model is not registered with the model registry.
- The model training pipeline is then run with pipeline.start, which invokes and instantiates all the preceding steps.
Batch transform
The batch transform pipeline consists of the following steps:
- The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
- The latest model registered in the model registry from the training pipeline is approved.
- A Transformer instance is used to runs a batch transform job to get inferences on the entire dataset stored in Amazon S3 from the data preparation step and store the output in Amazon S3.
SageMaker real-time inference
The SageMaker endpoint pipeline consists of the following steps:
- The latest approved model is retrieved from the model registry using the describe_model_package function from the SageMaker SDK.
- The latest approved model is deployed as a real-time SageMaker endpoint.
- The model is deployed on a ml.c5.xlarge instance with a minimum instance count of 1 and a maximum instance count of 3 (configurable by the user) with the automatic scaling policy set to ENABLED. This removes unnecessary instances so you don’t pay for provisioned instances that you aren’t using.
Prerequisites
To implement the solution provided in this post, you should have an AWS account, a SageMaker domain to access Amazon SageMaker Studio, and familiarity with SageMaker, Amazon S3, and PrestoDB.
The following prerequisites also need to be in place before running this code:
- PrestoDB – We use the built-in datasets available in PrestoDB through the TPCH connector for this solution. Follow the instructions in the GitHub README.md to set up PrestoDB on an Amazon Elastic Compute Cloud (Amazon EC2) instance in your account. If you already have access to a PrestoDB instance, you can skip this step but note its connection details (see the presto section in the config file). When you have your PrestoDB credentials, fill out the presto section in the config file as follows (enter your host public IP, port, credentials, catalog and schema):
- VPC network configurations – We also define the encryption, network isolation, and VPC configurations of the ML model and operations in the config file. For more information on network configurations and preferences, refer to Connect to SageMaker Within your VPC. If you are using the default VPC and security groups then you can leave these configuration parameters empty, see example in this configuration file. If not, then in the
awssection, specify theenable_network_isolationstatus,security_group_ids, and subnets based on your network isolation preferences. :
- IAM role – Set up an AWS Identity and Access Management (IAM) role with appropriate permissions to allow SageMaker to access AWS Secrets Manager, Amazon S3, and other services within your AWS account. Until an AWS CloudFormation template is provided that creates the role with the requisite IAM permissions, use a SageMaker role that allows the
AmazonSageMakerFullAccessAWS managed policy for your role. - Secrets Manager secret – Set up a secret in Secrets Manager for the PrestoDB user name and password. Call the secret prestodb-credentials and add a username field and password field to it. For instructions, refer to Create and manage secrets with AWS Secrets Manager.
Deploy the solution
Complete the following steps to deploy the solution:
- Clone the GitHub repository in SageMaker Studio. For instructions, see Clone a Git Repository in SageMaker Studio Classic.
- Edit the
config.ymlfile as follows:- Edit the parameter values in the presto section. These parameters define the connectivity to PrestoDB.
- Edit the parameter values in the
awssection. These parameters define the network connectivity, IAM role, bucket name, AWS Region, and other AWS Cloud-related parameters. - Edit the parameter values in the sections corresponding to the pipeline steps (
training_step, tuning_step, transform_step, and so on). - Review all the parameters in these sections carefully and edit them as appropriate for your use case.
When the prerequisites are complete and the config.yml file is set up correctly, you’re ready to run the mlops-pipeline-prestodb solution. The following architecture diagram provides a visual representation of the steps that you implement.
The diagram shows the following three steps:
- Part 1: Training – This pipeline includes the data preprocessing step, the training and tuning step, the model evaluation step, the condition step, and the register model step. The train, test, and validation datasets and evaluation report that are generated in this pipeline are sent to an S3 bucket.
- Part 2: Batch transform – This pipeline includes the batch data preprocessing step, approving the latest model from the model registry, creating the model instance, and performing batch transformation on data that is stored and retrieved from an S3 bucket.
- The PrestoDB server is hosted on an EC2 instance, with credentials stored in Secrets Manager.
- Part 3: SageMaker real-time inference – Finally, the latest approved model from the SageMaker model registry is deployed as a SageMaker real-time endpoint for inference.
Test the solution
In this section, we walk through the steps of running the solution.
Training pipeline
Complete the following steps to run the training pipeline
(0_model_training_pipeline.ipynb):
- On the SageMaker Studio console, choose
0_model_training_pipeline.ipynbin the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook demonstrates how you can use SageMaker Pipelines to string together a sequence of data processing, model training, tuning, and evaluation steps to train a binary classification ML model using scikit-learn.
At the end of this run, navigate to pipelines in the navigation pane. Your pipeline structure on SageMaker Pipelines should look like the following figure.
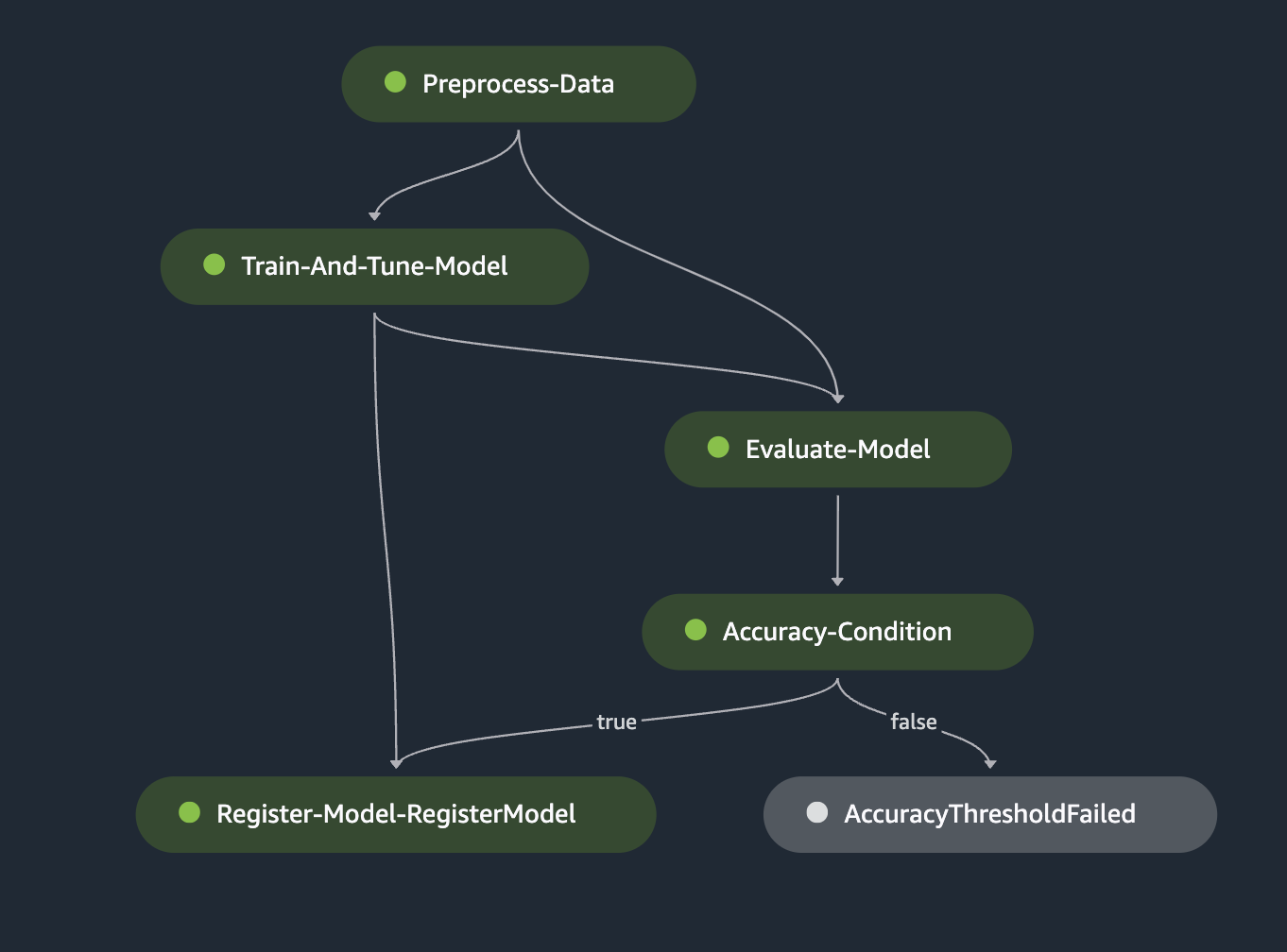
The training pipeline consists of the following steps that are implemented through the notebook run:
- Preprocess the data – In this step, we create a processing job for data preprocessing. For more information on processing jobs, see Process data. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. This step splits and sends data retrieved from PrestoDB as train, test, and validation files to an S3 bucket. The ML model is trained using the data in these files.
- The sklearn_processor is used in the ProcessingStep to run the scikit-learn script that preprocesses data. The step is defined as follows:
Here, we use config['scripts']['source_dir'], which points to the data preprocessing script that connects to the PrestoDB instance. Parameters used as arguments in step_args are configurable and fetched from the config file.
- Train the model – In this step, we create a training job to train a model. For more information on training jobs, see Train a Model with Amazon SageMaker. Here, we use the Scikit Learn Estimator from the SageMaker SDK to handle the end-to-end training and deployment of custom Scikit-learn code. The
RandomForestClassifieris used to train the ML model for our binary classification use case. TheHyperparameterTunerclass is used for running automatic model tuning to determine the set of hyperparameters that provide the best performance based on a user-defined metric threshold (for example, maximizing the AUC metric).
In the following code, the sklearn_estimator object is used with parameters that are configured in the config file and uses a training script to train the ML model. This step accesses the train, test, and validation files that were created as a part of the previous data preprocessing step.
- Evaluate the model – This step checks if the trained and tuned model has an accuracy level above a user-defined threshold, and only then registers the model with the model registry. If the model accuracy doesn’t meet the user-defined threshold, the pipeline fails and the model is not registered with the model registry. We use the ScriptProcessor with an evaluation script that a user creates to evaluate the trained model based on a metric of choice.
The evaluation step uses the evaluation script as a code entry. This script prepares the features and target values, and calculates the prediction probabilities using model.predict. At the end of the run, an evaluation report is sent to Amazon S3 that contains information on precision, recall, and accuracy metrics.
The following screenshot shows an example of an evaluation report.

- Add conditions – After the model is evaluated, we can add conditions to the pipeline with a ConditionStep. This step registers the model only if the given user-defined metric threshold is met. In our solution, we only want to register the new model version with the model registry if the new model meets a specific accuracy condition of above 70%.
If the accuracy condition is not met, a step_fail step is run that sends an error message to the user, and the pipeline fails. For instance, because the user-defined accuracy condition is set to 0.7 in the config file, and the accuracy calculated during the evaluation step exceeds it (73.8%), the outcome of this step is set to True and the model moves to the last step of the training pipeline.
- Register the model – The
RegisterModelstep registers a sagemaker.model.Model or a sagemaker.pipeline.PipelineModel with the SageMaker model registry. When the trained model meets the model performance requirements, a new version of the model is registered with the SageMaker model registry.
The model is registered with the model registry with an approval status set to PendingManualApproval. This means the model can’t be deployed on a SageMaker endpoint unless its status in the registry is changed to Approved manually on the SageMaker console, programmatically, or through an AWS Lambda function.
Now that the model is registered, you can get access to the registered model manually on the SageMaker Studio model registry console or programmatically in the next notebook, approve it, and run the batch transform pipeline.
Batch transform pipeline
Complete the following steps to run the batch transform pipeline (1_batch_transform_pipeline.ipynb):
- On the SageMaker Studio console, choose
1_batch_transform_pipeline.ipynbin the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook will run a batch transform pipeline using the model trained in the previous notebook.
At the end of the batch transform pipeline, your pipeline structure on SageMaker Pipelines should look like the following figure.
![]()
The batch transform pipeline consists of the following steps that are implemented through the notebook run:
- Extract the latest approved model from the SageMaker model registry – In this step, we extract the latest model from the model registry and set the
ModelApprovalStatustoApproved:
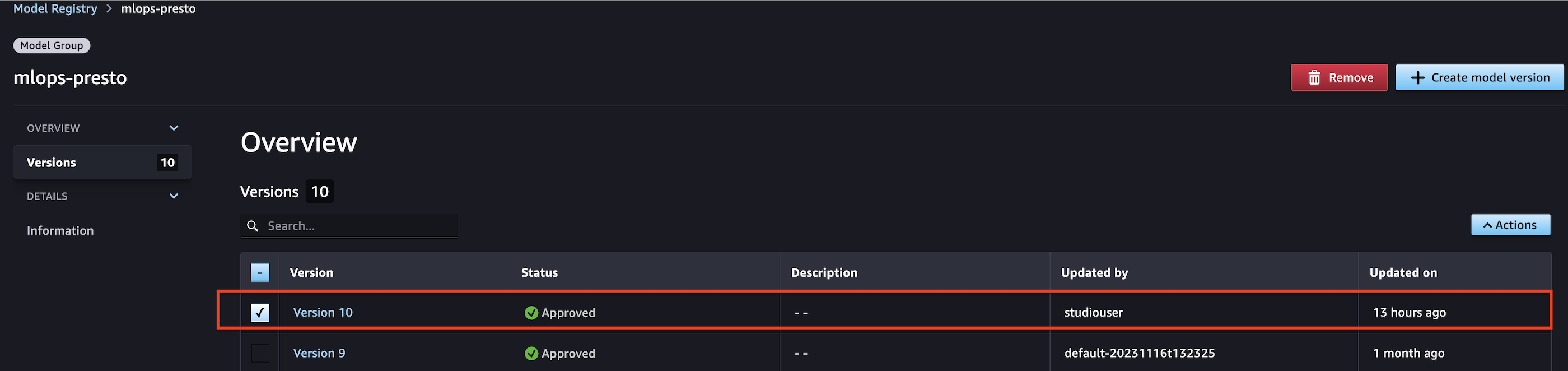
Now we have extracted the latest model from the SageMaker model registry and programmatically approved it. You can also approve the model manually on the SageMaker model registry page in SageMaker Studio as shown in the following screenshot.
- Read raw data for inference from PrestoDB and store it in an S3 bucket – After the latest model is approved, batch data is fetched from the PrestoDB instance and used for the batch transform step. In this step, we use a batch preprocessing script that queries data from PrestoDB and saves it in a batch directory within an S3 bucket. The query that is used to fetch batch data is configured by the user within the config file in the
transform_stepsection:
After the batch data is extracted into the S3 bucket, we create a model instance and point to the inference.py script, which contains code that runs as part of getting inference from the trained model:
- Create a batch transform step to perform inference on the batch data stored in Amazon S3 – Now that a model instance is created, create a Transformer instance with the appropriate model type, compute instance type, and desired output S3 URI. Specifically, pass in the
ModelNamefrom the CreateModelStepstep_create_modelproperties. TheCreateModelStepproperties attribute matches the object model of theDescribeModelresponse object. Use a transform step for batch transformation to run inference on an entire dataset. For more information about batch transform, see Run Batch Transforms with Inference Pipelines. - A transform step requires a transformer and the data on which to run batch inference:
Now that the transformer object is created, pass the transformer input (which contains the batch data from the batch preprocess step) into the TransformStep declaration. Store the output of this pipeline in an S3 bucket.
SageMaker real-time inference
Complete the following steps to run the real-time inference pipeline (2_realtime_inference.ipynb):
- On the SageMaker Studio console, choose
2_realtime_inference_pipeline.ipynb in the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook extracts the latest approved model from the model registry and deploys it as a SageMaker endpoint for real-time inference. It does so by completing the following steps:
- Extract the latest approved model from the SageMaker model registry – To deploy a real-time SageMaker endpoint, first fetch the image URI of your choice and extract the latest approved model from the model registry. After the latest approved model is extracted, we use a container list with the specified inference.py as the script for the deployed model to use at inference. This model creation and endpoint deployment are specific to the scikit-learn model configuration.
- In the following code, we use the
inference.pyfile specific to the scikit-learn model. We then create our endpoint configuration, setting ourManagedInstanceScalingtoENABLEDwith our desiredMaxInstanceCountandMinInstanceCountfor automatic scaling:
- Run inference on the deployed real-time endpoint – After you have extracted the latest approved model, created the model from the desired image URI, and configured the endpoint configuration, you can deploy it as a real-time SageMaker endpoint:
Upon deployment, you can view the endpoint in service on the SageMaker Endpoints page.

Now you can run inference against the data extracted from PrestoDB:
Results
Here is an example of an inference request and response from the real time endpoint using the implementation above:
Inference request format (view and change this example as you would like for your custom use case)
Response from the real time endpoint
Clean up
To clean up the endpoint used in this solution to avoid extra charges, complete the following steps:
- On the SageMaker console, choose Endpoints in the navigation pane.
- Select the endpoint to delete.
- On the Actions menu, choose Delete.

{kind=link}
Conclusion
In this post, we demonstrated an end-to-end MLOps solution on SageMaker. The process involved fetching data by connecting a SageMaker Processing job to a PrestoDB instance, followed by training, evaluating, and registering the model. We approved the latest registered model from the training pipeline and ran batch inference against it using batch data queried from PrestoDB and stored in Amazon S3. Lastly, we deployed the latest approved model as a real-time SageMaker endpoint to run inferences.
The rise of generative AI increases the demand for training, deploying, and running ML models, and consequently, the use of data. By integrating SageMaker Processing jobs with PrestoDB, you can seamlessly migrate your workloads to SageMaker pipelines without additional data preparation, storage, or accessibility burdens. You can build, train, evaluate, run batch inferences, and deploy models as real-time endpoints while using your existing data engineering pipelines with minimal or no code changes.
Explore SageMaker Pipelines and open source data querying engines like PrestoDB, and build a solution using the sample implementation provided.
Get started today by referring to the GitHub repository.
For more information and tutorials on SageMaker Pipelines, refer to the SageMaker Pipelines documentation.
About the Authors
 Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Antara Raisa is an AI and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital-centered customers.
Antara Raisa is an AI and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital-centered customers.
 Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and AI.
Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and AI.
 Shamik Ray is a Senior Engineering Manager at Twilio, leading the Data Science and ML team. With 12 years of experience in software engineering and data science, he excels in overseeing complex machine learning projects and ensuring successful end-to-end execution and delivery.
Shamik Ray is a Senior Engineering Manager at Twilio, leading the Data Science and ML team. With 12 years of experience in software engineering and data science, he excels in overseeing complex machine learning projects and ensuring successful end-to-end execution and delivery.
 Srivyshnav K S is a Senior Machine Learning Engineer at Twilio with over 5 years of experience. His expertise lies in leveraging statistical and machine learning techniques to develop advanced models for detecting patterns and anomalies. He is adept at building projects end-to-end.
Srivyshnav K S is a Senior Machine Learning Engineer at Twilio with over 5 years of experience. His expertise lies in leveraging statistical and machine learning techniques to develop advanced models for detecting patterns and anomalies. He is adept at building projects end-to-end.
 Jagmohan Dhiman is a Senior Data Scientist with 7 years of experience in machine learning solutions. He has extensive expertise in building end-to-end solutions, encompassing data analysis, ML-based application development, architecture design, and MLOps pipelines for managing the model lifecycle.
Jagmohan Dhiman is a Senior Data Scientist with 7 years of experience in machine learning solutions. He has extensive expertise in building end-to-end solutions, encompassing data analysis, ML-based application development, architecture design, and MLOps pipelines for managing the model lifecycle.
 Soumya Kundu is a Senior Data Engineer with almost 10 years of experience in Cloud and Big Data technologies. He specialises in AI/ML based large scale Data Processing systems and an avid IoT enthusiast in his spare time.
Soumya Kundu is a Senior Data Engineer with almost 10 years of experience in Cloud and Big Data technologies. He specialises in AI/ML based large scale Data Processing systems and an avid IoT enthusiast in his spare time.