

{kind=link}
Amazon Bedrock Guardrails announces the general availability of image content filters, enabling you to moderate both image and text content in your generative AI applications. Previously limited to text-only filtering, this enhancement now provides comprehensive content moderation across both modalities. This new capability removes the heavy lifting required to build your own image safeguards or spend cycles on manual content moderation that can be error-prone and tedious.
Tero Hottinen, VP, Head of Strategic Partnerships at KONE, envisions the following use case:
“In its ongoing evaluation, KONE recognizes the potential of Amazon Bedrock Guardrails as a key component in protecting generative AI applications, particularly for relevance and contextual grounding checks, as well as the multimodal safeguards. The company envisions integrating product design diagrams and manuals into its applications, with Amazon Bedrock Guardrails playing a crucial role in enabling more accurate diagnosis and analysis of multimodal content.”
Amazon Bedrock Guardrails provides configurable safeguards to help customers block harmful or unwanted inputs and outputs for their generative AI applications. Customers can create custom Guardrails tailored to their specific use cases by implementing different policies to detect and filter harmful or unwanted content from both input prompts and model responses. Furthermore, customers can use Guardrails to detect model hallucinations and help make responses grounded and accurate. Through its standalone ApplyGuardrail API, Guardrails enables customers to apply consistent policies across any foundation model, including those hosted on Amazon Bedrock, self-hosted models, and third-party models. Bedrock Guardrails supports seamless integration with Bedrock Agents and Bedrock Knowledge Bases, enabling developers to enforce safeguards across various workflows, such as Retrieval Augmented Generation (RAG) systems and agentic applications.
Amazon Bedrock Guardrails offers six distinct policies, including: content filters to detect and filter harmful material across several categories, including hate, insults, sexual content, violence, misconduct, and to prevent prompt attacks; topic filters to restrict specific subjects; sensitive information filters to block personally identifiable information (PII); word filters to block specific terms; contextual grounding checks to detect hallucinations and analyze response relevance; and Automated Reasoning checks (currently in gated preview) to identify, correct, and explain factual claims. With the new image content moderation capability, these safeguards now extend to both text and images, helping customer block up to 88% of harmful multimodal content. You can independently configure moderation for either image or text content (or both) with adjustable thresholds from low to high, helping you to build generative AI applications that align with your organization’s responsible AI policies.
This new capability is generally available in US East (N. Virginia), US West (Oregon), Europe (Frankfurt), and Asia Pacific (Tokyo) AWS Regions.
In this post, we discuss how to get started with image content filters in Amazon Bedrock Guardrails.
Solution overview
To get started, create a guardrail on the AWS Management Console and configure the content filters for either text or image data or both. You can also use AWS SDKs to integrate this capability into your applications.
Create a guardrail
To create a guardrail, complete the following steps:
- On the Amazon Bedrock console, under Safeguards in the navigation pane, choose Guardrails.
- Choose Create guardrail.
- In the Configure content filters section, under Harmful categories and Prompt attacks, you can use the existing content filters to detect and block image data in addition to text data.
- After you’ve selected and configured the content filters you want to use, you can save the guardrail and start using it to help you block harmful or unwanted inputs and outputs for your generative AI applications.
Test a guardrail with text generation
To test the new guardrail on the Amazon Bedrock console, select the guardrail and choose Test. You have two options: test the guardrail by choosing and invoking a model or test the guardrail without invoking a model by using the Amazon Bedrock Guardrails independent ApplyGuardail API.
With the ApplyGuardrail API, you can validate content at any point in your application flow before processing or serving results to the user. You can also use the API to evaluate inputs and outputs for self-managed (custom) or third-party FMs, regardless of the underlying infrastructure. For example, you could use the API to evaluate a Meta Llama 3.2 model hosted on Amazon SageMaker or a Mistral NeMo model running on your laptop.
Test a guardrail by choosing and invoking a model
Select a model that supports image inputs or outputs, for example, Anthropic’s Claude 3.5 Sonnet. Verify that the prompt and response filters are enabled for image content. Then, provide a prompt, upload an image file, and choose Run.

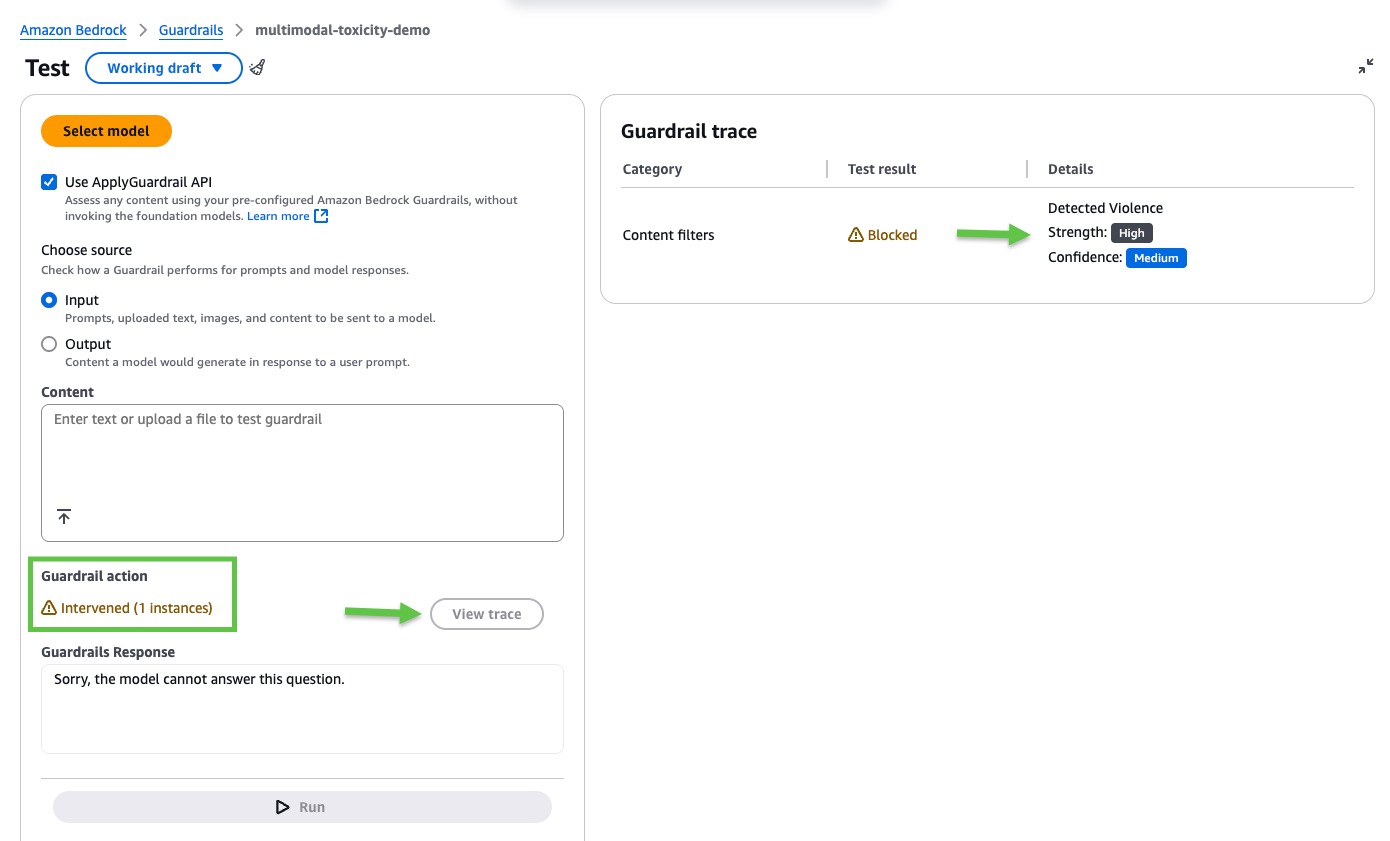
In this example, Amazon Bedrock Guardrails intervened. Choose View trace for more details.
The guardrail trace provides a record of how safety measures were applied during an interaction. It shows whether Amazon Bedrock Guardrails intervened or not and what assessments were made on both input (prompt) and output (model response). In this example, the content filters blocked the input prompt because they detected violence in the image with medium confidence.

Test a guardrail without invoking a model
On the Amazon Bedrock console, choose Use ApplyGuardail API, the independent API to test the guardrail without invoking a model. Choose whether you want to validate an input prompt or an example of a model generated output. Then, repeat the steps from the previous section. Verify that the prompt and response filters are enabled for image content, provide the content to validate, and choose Run.

For this example, we reused the same image and input prompt, and Amazon Bedrock Guardrails intervened again. Choose View trace again for more details.
Test a guardrail with image generation
Now, let’s test the Amazon Bedrock Guardrails multimodal toxicity detection with image generation use cases. The following is an example of using Amazon Bedrock Guardrails image content filters with an image generation use case. We generate an image using the Stability model on Amazon Bedrock using the InvokeModel API and the guardrail:
You can access the complete example from the GitHub repo.
Conclusion
In this post, we explored how Amazon Bedrock Guardrails’ new image content filters provide comprehensive multimodal content moderation capabilities. By extending beyond text-only filtering, this solution now helps customers block up to 88% of harmful or unwanted multimodal content across configurable categories including hate, insults, sexual content, violence, misconduct, and prompt attack detection. Guardrails can help organizations across healthcare, manufacturing, financial services, media, and education enhance brand safety without the burden of building custom safeguards or conducting error-prone manual evaluations.
To learn more, see Stop harmful content in models using Amazon Bedrock Guardrails.
About the Authors
 Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures.
Satveer Khurpa is a Sr. WW Specialist Solutions Architect, Amazon Bedrock at Amazon Web Services, specializing in Amazon Bedrock security. In this role, he uses his expertise in cloud-based architectures to develop innovative generative AI solutions for clients across diverse industries. Satveer’s deep understanding of generative AI technologies and security principles allows him to design scalable, secure, and responsible applications that unlock new business opportunities and drive tangible value while maintaining robust security postures.
 Shyam Srinivasan is on the Amazon Bedrock Guardrails product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
Shyam Srinivasan is on the Amazon Bedrock Guardrails product team. He cares about making the world a better place through technology and loves being part of this journey. In his spare time, Shyam likes to run long distances, travel around the world, and experience new cultures with family and friends.
 Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at AWS. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at AWS. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
 Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use case-driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.
Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use case-driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.